What is Cassandra?
The Apache Cassandra database is the right choice when you need scalability and high availability without
compromising performance. Linear scalability
and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for
mission-critical data.Cassandra's support for replicating across multiple datacenters is best-in-class, providing
lower latency for your users and the peace of mind of knowing that you can survive regional outages. Casandra is NoSql database.
- All the nodes in a cluster play the same role. Each node is independent and at the same time interconnected to other nodes.
- Each node in a cluster can accept read and write requests, regardless of where the data is actually located in the cluster.
- When a node goes down, read/write requests can be served from other nodes in the network.
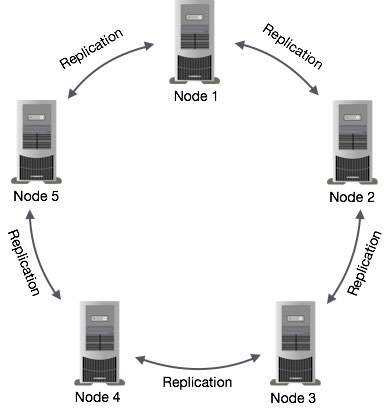
Data Replication in Cassandra
In Cassandra, one or more of the nodes in a cluster act as replicas for a given piece of data. If it is detected that some of the nodes responded with an out-of-date value, Cassandra will return the most recent value to the client. After returning the most recent value, Cassandra performs a read repair in the background to update the stale values.The following figure shows a schematic view of how Cassandra uses data replication among the nodes in a cluster to ensure no single point of failure.
Components of Cassandra
The key components of Cassandra are as follows −- Node − It is the place where data is stored.
- Data center − It is a collection of related nodes.
- Cluster − A cluster is a component that contains one or more data centers.
- Commit log − The commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
- Mem-table − A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
- SSTable − It is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
- Bloom filter − These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
Cassandra Query Language
Users can access Cassandra through its nodes using Cassandra Query Language (CQL). CQL treats the database (Keyspace) as a container of tables. Programmers use cqlsh: a prompt to work with CQL or separate application language drivers.Clients approach any of the nodes for their read-write operations. That node (coordinator) plays a proxy between the client and the nodes holding the data.
Write Operations
Every write activity of nodes is captured by the commit logs written in the nodes. Later the data will be captured and stored in the mem-table. Whenever the mem-table is full, data will be written into the SStable data file. All writes are automatically partitioned and replicated throughout the cluster. Cassandra periodically consolidates the SSTables, discarding unnecessary data.Read Operations
How Does Cassandra Differ From a Relational Database?
Although the non-relational databases in the market today provide
different features and benefits, a database like Cassandra differs from a
typical relational database in the following ways:
Table 1. Table A quick comparison of RDBMS and a NoSQL database like Cassandra.
| Relational Database | Cassandra |
|---|---|
Handles moderate incoming data velocity
|
Handles high incoming data velocity
|
Data arriving from one/few locations
|
Data arriving from many locations
|
Manages primarily structured data
|
Manages all types of data
|
Supports complex/nested transactions
|
Supports simple transactions
|
Single points of failure with failover
|
No single points of failure; constant uptime
|
Supports moderate data volumes
|
Supports very high data volumes
|
Centralized deployments
|
Decentralized deployments
|
Data written in mostly one location
|
Data written in many locations
|
Supports read scalability (with consistency sacrifices)
|
Supports read and write scalability
|
Deployed in vertical scale up fashion
|
Deployed in horizontal scale out fashion
|
Key Cassandra Features and Benefits
Cassandra provides a number of key features and benefits for those
looking to use it as the underlying database for modern online
applications:
-
Massively scalable architecture – a masterless design where all nodes
are the same, which provides operational simplicity and easy scale-out.
-
Active everywhere design – all nodes may be written to and read from.
-
Linear scale performance – the ability to add nodes without going down produces predictable increases in performance.
-
Continuous availability – offers redundancy of both data and node
function, which eliminate single points of failure and provide constant
uptime.
-
Transparent fault detection and recovery – nodes that fail can easily be restored or replaced.
-
Flexible and dynamic data model – supports modern data types with fast writes and reads.
-
Strong data protection – a commit log design ensures no data loss and
built in security with backup/restore keeps data protected and safe.
-
Tunable data consistency – support for strong or eventual data consistency across a widely distributed cluster.
-
Multi-data center replication – cross data center (in multiple
geographies) and multi-cloud availability zone support for writes/reads.
-
Data compression – data compressed up to 80% without performance overhead.
-
CQL (Cassandra Query Language) – an SQL-like language that makes moving from a relational database very easy.
Top Use Cases
While Cassandra is a general purpose non-relational database that can
be used for a variety of different applications, there are a number of
use cases where the database excels over most any other option. These
include:
-
Internet of things applications – Cassandra is perfect for consuming
lots of fast incoming data from devices, sensors and similar mechanisms
that exist in many different locations.
-
Product catalogs and retail apps – Cassandra is the database of
choice for many retailers that need durable shopping cart protection,
fast product catalog input and lookups, and similar retail app support.
-
User activity tracking and monitoring – many media and entertainment
companies use Cassandra to track and monitor the activity of their
users’ interactions with their movies, music, website and online
applications.
-
Messaging – Cassandra serves as the database backbone for numerous mobile phone and messaging providers’ applications.
-
Social media analytics and recommendation engines – many online
companies, websites, and social media providers use Cassandra to ingest,
analyze, and provide analysis and recommendations to their customers.
-
Other time-series-based applications – because of Cassandra’s fast
write capabilities, wide-row design, and ability to read only the
columns needed to satisfy queries, it is well suited time series based
applications.
0 comments:
Post a Comment